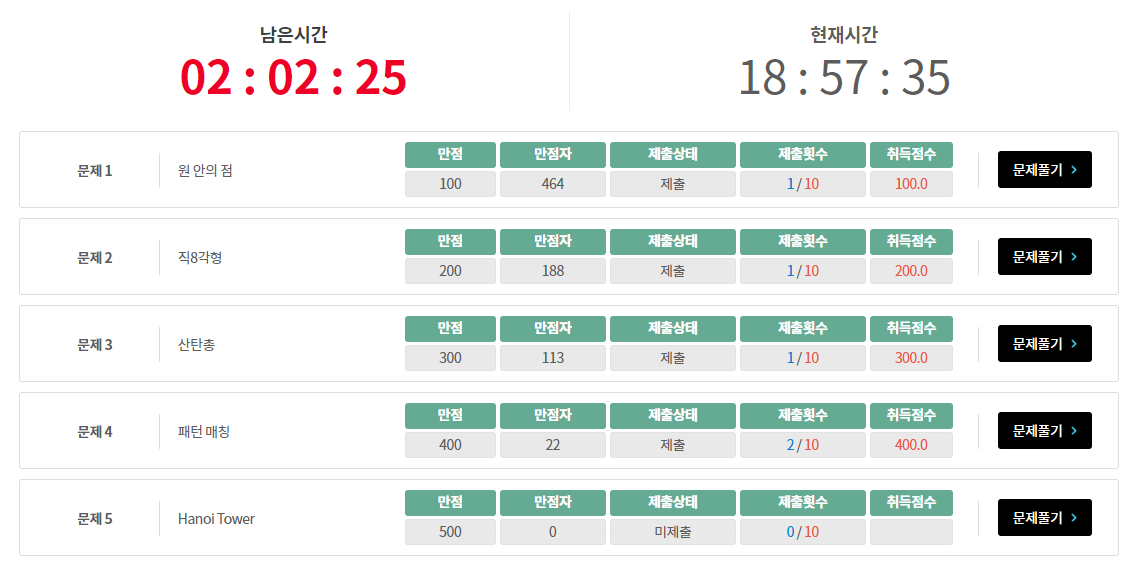
5번은 긁기는 쉬운데 만점을 받는 사람이 없길래 그냥 건드리지 않았다. 4번도 풀었고 ^__^
1번 : 원 안의 점
naive 하게 $-R \le x, y \le R$인 점을 모두 시도하면 $\mathcal{O}(R^2)$ 풀이가 나온다.
답을 $\mathcal{O}(R)$에 구하기 위해서는, $x$ 하나를 고정하고 가능한 $y$의 개수를 $\mathcal{O}(1)$에 구하면 된다.
$x^2+y^2 \le R^2-1 \iff -\sqrt{R^2-1-x^2} \le y \le \sqrt{R^2 -1-x^2}$임을 계산하면, 가능한 $y$의 개수가 $$2 \lfloor \sqrt{R^2 - 1 - x^2} \rfloor + 1$$임을 알 수 있다. 이는 sqrt 함수를 사용하거나 이분탐색을 해서 빠르게 계산할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
#include <bits/stdc++.h>
#define fio ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
using namespace std;
typedef long long int ll;
typedef unsigned long long int ull;
typedef long double ldb;
const ll mod = 1e9 + 7;
ll calc(ll x)
{
ll lef=0, rig=1e9, best=0, mid;
while(lef<=rig)
{
mid = (lef + rig) / 2;
if(mid * mid <= x)
{
best = mid;
lef = mid + 1;
}
else rig = mid - 1;
}
return best;
}
void solve(void)
{
ll R, ans=0; cin >> R;
for(ll i=-R+1 ; i<=R-1 ; i++)
ans += 2 * calc(R * R - 1 - i * i) + 1;
cout << ans << endl;
}
int main(void)
{
fio; ll i, tc; cin >> tc;
for(i=1 ; i<=tc ; i++)
{
cout << "Case #" << i << endl;
solve(); // endl in solve
}
return 0;
}
|
cs |
2번 : 직8각형
점 $(x_1, y_1), \cdots (x_8, y_8)$이 있을 때, 적당한 $X, Y$를 골라서 이 점들을 $$(X, Y), (X, Y+K), (X+K, Y+2K), (X+2K, Y+2K)$$ $$(X+3K, Y+K), (X+3K, Y), (X+2K, Y-K), (X+K, Y-K)$$와 같도록 해야 한다. 각 8개의 점을 직8각형의 8개의 점에 대응시키는 방법에는 총 $8!$가지가 있다. 이러한 방법을 하나 고정시키고 생각하자.
예를 들어, $(x_1, y_1), \cdots , (x_8, y_8)$이 위 8개의 점과 순서대로 대응된다고 가정하자. 이 경우, 움직여야 하는 총 거리는 $$|x_1 - X| + |y_1 - Y| + |x_2 - X| + |y_2 - (Y+K)| + |x_3 - (X+K)| + |y_3 - (Y+2K)|$$ $$+|x_4 - (X+2K)| + |y_4 - (Y+2K)| + |x_5 - (X+3K)| + |y_5 - (Y+K)| + |x_6 - (X+3K)| + |y_6 - Y|$$ $$+|x_7 - (X+2K)| + |y_7 - (Y-K)| + |x_8 - (X+K)| + |y_8 - (Y-K)|$$가 되며, 우리의 목표는 이 식의 최솟값을 구하는 것이다.
첫 번째 관찰은 위 식에서 $X, Y$가 각각 독립적으로 나온다는 것이다. 위 식에서 $X$가 등장하는 부분만 살펴보면, $$|X-x_1| + |X-x_2| + |X - (x_3-K)| + |X - (x_4-2K)|$$ $$+ |X - (x_5-3K)| + |X - (x_6-3K)| + |X - (x_7 - 2K)| + |X - (x_8 -K)|$$ 두 번째 관찰은, $x_i$들과 $K$가 이미 알고 있는 값이므로, 이 식은 이미 알고 있는 값 $c_1, c_2, \cdots, c_8$에 대해 $$\sum_{i=1}^8 |X - c_i|$$ 형태로 쓸 수 있다는 것이다. 이 식은 $X$가 $c_i$들의 "중간"에 있을 때 최솟값을 가진다.
확인하고 싶다면, 위 식을 그래프로 그려보자. 또한, 이 때 최솟값은 $c_i$들 중 최대 4개에서 최소 4개를 뺀 값이 됨을 확인할 수 있다.
$Y$에 대한 부분도 이렇게 최솟값을 구할 수 있으며, 두 결과를 합치면 식의 최솟값을 구할 수 있다. 이를 $8!$번 반복하면 해결.
시간복잡도는 $n$이 점의 개수라고 하면, $\mathcal{O}(n! \cdot n \log n)$ 정도로 볼 수 있을 것이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
#include <bits/stdc++.h>
#define fio ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
using namespace std;
typedef long long int ll;
typedef unsigned long long int ull;
typedef long double ldb;
const ll mod = 1e9 + 7;
pair<ll, ll> pts[8]; ll K;
ll x[8], y[8];
ll difx[8] = {0, 0, 1, 2, 3, 3, 2, 1};
ll dify[8] = {0, 1, 2, 2, 1, 0, -1, -1};
void solve(void)
{
ll i, ans=1e18; cin >> K;
for(i=0 ; i<8 ; i++) cin >> pts[i].first >> pts[i].second;
sort(pts, pts+8);
do
{
for(i=0 ; i<8 ; i++) x[i] = pts[i].first - difx[i] * K;
for(i=0 ; i<8 ; i++) y[i] = pts[i].second - dify[i] * K;
sort(x, x+8); sort(y, y+8);
ll cur = 0;
for(i=4 ; i<8 ; i++) cur += (x[i] + y[i]);
for(i=0 ; i<4 ; i++) cur -= (x[i] + y[i]);
ans = min(ans, cur);
} while(next_permutation(pts, pts+8));
cout << ans << endl;
}
int main(void)
{
fio; ll i, tc; cin >> tc;
for(i=1 ; i<=tc ; i++)
{
cout << "Case #" << i << endl;
solve(); // endl in solve
}
return 0;
}
|
cs |
3번 : 산탄총
정말 피곤한 문제였다. 진짜 부분합만 알면 풀 수 있는데, 깔끔하게 안 풀어서 그런지 계산이 너무 귀찮았다.
이제부터 모든 것을 수식으로 설명한다. 하지만 실제로 문제를 풀거나 이 풀이를 읽을 때는 그림을 그려가면서 생각하는 것이 좋을 것이다.
배열은 1-index를 사용하여, $1 \le i, j \le N$에 배열 $a$가 채워졌다고 생각하도록 하겠다.
우선, 목표로 하는 함수인 $$ \text{score}(Y, X) = \sum_{|y-Y| + |x-X| \le K-1} (K-|y-Y|-|x-X|) \cdot a[y][x]$$를 정의하면, 우리의 목표는 $\text{score}$의 최댓값을 찾는 것이다. 우선 $Y$ 또는 $X$가 $-K$ 미만이거나 $N+K$ 초과면, $\text{score}$ 함수가 $0$이 됨을 확인할 수 있다.
그러니 $-K \le X, Y \le N+K$인 경우만 계산하면 된다. 우리의 궁극적인 목표는 $\text{score}$ 함수를 이 범위 전체에 대해서 $\mathcal{O}((N+K)^2) = \mathcal{O}(N^2)$ 시간에 계산하는 것이다. 이를 위해서는 $\text{score}$ 함수가 $(Y, X)$가 한 칸 움직였을 때 어떻게 변화하는지 알아볼 필요가 있다.
$$\text{score}(Y, X) - \text{score}(Y, X-1)$$ $$= \sum_{|y-Y| + |x-X| \le K-1} (K-|y-Y|-|x-X|) \cdot a[y][x] - \sum_{|y-Y| + |x-X+1| \le K-1} (K - |y-Y| - |x-X+1|) \cdot a[y][x]$$
이 값을 분석하는 가장 좋은 방법은 각 $(y, x)$에 대해 $a[y][x]$의 계수를 찾는 것이다. 그림을 그려 풀 때도 비슷하다.
우선 생각해보면 $|y-Y|+|x-X|$와 $|y-Y|+|x-(X-1)|$이 모두 $K$ 이하인 경우, $a[y][x]$의 계수는 $$|x-X+1| - |x-X|$$가 된다. 이 값은 $x \ge X$에서 $1$이고 $x \le X-1$에서 $-1$임을 알 수 있다.
$|y-Y|+|x-X|$나 $|y-Y|+|x-(X-1)|$ 중 하나라도 $K+1$ 이상인 경우, 둘 다 $K$ 이상이 되어 계수는 $0$이다. 즉,
$$\text{score}(Y, X) - \text{score}(Y, X-1) = \sum_{|y-Y| + |x-X| \le K-1, x \ge X} a[y][x] - \sum_{|y-Y| + |x-X+1| \le K-1, x \le X-1} a[y][x] $$가 되고, 비슷한 원리로 계산하면 $$\text{score}(Y, X) - \text{score}(Y-1, X) = \sum_{|y-Y|+|x-X| \le K-1, y \ge Y} a[y][x] - \sum_{|y-Y+1|+|x-X| \le K-1, y \le Y-1} a[y][x]$$를 얻는다. 그러니까 이제 필요한 것은 네 종류의 "삼각형 부분합"이며, 이들 역시 같은 방법으로 계산이 가능하다.
예를 들어, "1사분면에 대한 삼각형 부분합"을 $$Q1(Y, X) = \sum_{|y-Y| + |x-X| \le K-1, y \le Y, x \ge X} a[y][x]$$라 하자. 이 값을 계산하기 위하여, 다시 인접한 $Q1$ 값의 차이를 계산해보면, $$Q1(Y, X) - Q1(Y, X-1) = \sum_{|y-Y| + |x-X| \le K-1, y \le Y, x \ge X} a[y][x] - \sum_{|y-Y| + |x-X+1| \le K-1, y \le Y, x \ge X-1} a[y][x]$$인데, $a[y][x]$의 계수를 생각해보면 다음과 같은 결과를 얻을 수 있다. 그림을 그려서 생각하는 게 편하다.
- $x \ge X, y \le Y$이고 $(Y-y) + (x-X) = |y-Y|+|x-X| = K-1$이면 계수가 $+1$
- $x = X-1$이고 $Y-K+1 \le y \le Y$면 계수가 $-1$
- 나머지 경우에 대해서는 전부 계수가 $0$
첫 번째 경우에 대한 합은 "대각선 부분합"이고, 두 번째 경우에 대한 합은 "일직선 부분합"이니, 전부 부분합 테크닉으로 빠르게 구할 수 있다.
그러니 $Q1(Y, X-1)$이 있으면 $Q1(Y, X)$를 구할 수 있고, 비슷한 계산으로 $Q1(Y-1, X)$이 있으면 $Q1(Y, X)$를 빠르게 구하는 식을 얻을 수 있다.
$Q1(-K, -K)$를 naive 하게 직접 구한 후 위 방법을 적용하면 모든 $Y, X$에 대해 $Q1(Y, X)$를 $\mathcal{O}(N^2)$에 구할 수 있다.
이를 각 4개의 사분면에 대해서 적용할 수 있고, 이제 $\text{score}$ 역시 전부 $\mathcal{O}(N^2)$에 구할 수 있다.
당연하지만 이 문제에서는 index가 범위를 벗어나는 것에 대한 처리가 매우 귀찮고 중요하다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
|
#include <bits/stdc++.h>
#define fio ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
using namespace std;
typedef long long int ll;
typedef unsigned long long int ull;
typedef long double ldb;
const ll mod = 1e9 + 7;
ll K, N;
ll val[1811][1811];
ll DIAG1[1811][1811]; // NW SE
ll DIAG2[1811][1811]; // NE SW
ll WE[1811][1811];
ll NS[1811][1811];
ll CALC[1811][1811];
ll QUAD[4][1811][1811];
void rset(void)
{
memset(val, 0, sizeof(val));
memset(DIAG1, 0, sizeof(DIAG1));
memset(DIAG2, 0, sizeof(DIAG2));
memset(WE, 0, sizeof(WE));
memset(NS, 0, sizeof(NS));
memset(CALC, 0, sizeof(CALC));
memset(QUAD, 0, sizeof(QUAD));
}
ll NS_p(ll Y1, ll Y2, ll X)
{
Y1 = min(Y1, N + 2 * K);
Y2 = max(Y2, 0LL);
return NS[Y1][X] - NS[Y2][X];
}
ll WE_p(ll Y, ll X1, ll X2)
{
X1 = min(X1, N + 2 * K);
X2 = max(X2, 0LL);
return WE[Y][X1] - WE[Y][X2];
}
ll getdiag1(ll Y1, ll X1)
{
if(Y1 < 0 || X1 < 0) return 0;
else if(Y1 <= N+2*K && X1 <= N+2*K) return DIAG1[Y1][X1];
else
{
ll offset = max(Y1 - (N + 2 * K), X1 - (N + 2 * K));
Y1 -= offset; X1 -= offset;
if(Y1 < 0 || X1 < 0) return 0;
else return DIAG1[Y1][X1];
}
}
ll DIAG1_p(ll Y1, ll X1, ll Y2, ll X2)
{
return getdiag1(Y1, X1) - getdiag1(Y2, X2);
}
ll getdiag2(ll Y1, ll X1)
{
if(Y1 < 0 || X1 > N + 2 * K) return 0;
else if(Y1 <= N+2*K && X1 >= 0) return DIAG2[Y1][X1];
else
{
ll offset = max(Y1 - (N + 2 * K), -X1);
Y1 -= offset; X1 += offset;
if(Y1 < 0 || X1 < 0 || X1 > N + 2 * K) return 0;
else return DIAG2[Y1][X1];
}
}
ll DIAG2_p(ll Y1, ll X1, ll Y2, ll X2)
{
return getdiag2(Y1, X1) - getdiag2(Y2, X2);
}
ll getval(ll Y, ll X)
{
if(X<=0 || X>N+2*K || Y<=0 || Y>N+2*K) return 0;
return val[Y][X];
}
void finish_QUAD0(void)
{
ll i, j;
for(i=0 ; i<=K-1 && i<=1 ; i++)
for(j=0 ; i+j<=K-1 ; j++)
QUAD[0][1][1] += getval(1-i, 1+j);
for(i=1 ; i<=N+2*K ; i++)
{
for(j=1 ; j<=N+2*K ; j++)
{
if(i == 1 && j == 1) continue;
if(j == 1) // get from top
{
QUAD[0][i][j] = QUAD[0][i-1][j]
+ WE_p(i, j+K-1, j-1)
- DIAG1_p(i-1, j+K-1, i-K-1, j-1);
}
else // get from left
{
QUAD[0][i][j] = QUAD[0][i][j-1]
+ DIAG1_p(i, j+K-1, i-K, j-1)
- NS_p(i, i-K, j-1);
}
}
}
}
void finish_QUAD1(void)
{
ll i, j;
for(i=0 ; i<=K-1 && i<=1 ; i++)
for(j=0 ; i+j<=K-1 && j<=1; j++)
QUAD[1][1][1] += getval(1-i, 1-j);
for(i=1 ; i<=N+2*K ; i++)
{
for(j=1 ; j<=N+2*K ; j++)
{
if(i == 1 && j == 1) continue;
if(j == 1) // get from top
{
QUAD[1][i][j] = QUAD[1][i-1][j]
+ WE_p(i, j, j-K)
- DIAG2_p(i-1, j-K+1, i-K-1, j+1);
}
else // get from left
{
QUAD[1][i][j] = QUAD[1][i][j-1]
+ NS_p(i, i-K, j)
- DIAG2_p(i, j-K, i-K, j);
}
}
}
}
void finish_QUAD2(void)
{
ll i, j;
for(i=0 ; i<=K-1 ; i++)
for(j=0 ; i+j<=K-1 && j<=1 ; j++)
QUAD[2][1][1] += getval(1+i, 1-j);
for(i=1 ; i<=N+2*K ; i++)
{
for(j=1 ; j<=N+2*K ; j++)
{
if(i == 1 && j == 1) continue;
if(j == 1) // get from top
{
QUAD[2][i][j] = QUAD[2][i-1][j]
+ DIAG1_p(i+K-1, j, i-1, j-K)
- WE_p(i-1, j, j-K);
}
else // get from left
{
QUAD[2][i][j] = QUAD[2][i][j-1]
+ NS_p(i+K-1, i-1, j)
- DIAG1_p(i+K-1, j-1, i-1, j-K-1);
}
}
}
}
void finish_QUAD3(void)
{
ll i, j;
for(i=0 ; i<=K-1 ; i++)
for(j=0 ; i+j<=K-1 ; j++)
QUAD[3][1][1] += val[1+i][1+j];
for(i=1 ; i<=N+2*K ; i++)
{
for(j=1 ; j<=N+2*K ; j++)
{
if(i == 1 && j == 1) continue;
if(j == 1) // get from top
{
QUAD[3][i][j] = QUAD[3][i-1][j]
+ DIAG2_p(i+K-1, j, i-1, j+K)
- WE_p(i-1, j+K-1, j-1);
}
else // get from left
{
QUAD[3][i][j] = QUAD[3][i][j-1]
+ DIAG2_p(i+K-1, j, i-1, j+K)
- NS_p(i+K-1, i-1, j-1);
}
}
}
}
void solve(void)
{
ll i, j; rset(); cin >> N >> K;
for(i=1 ; i<=N ; i++)
for(j=1 ; j<=N ; j++)
cin >> val[K+i][K+j];
for(i=0 ; i<=N+2*K ; i++)
{
for(j=0 ; j<=N+2*K ; j++)
{
if(i!=0 && j!=0) DIAG1[i][j] = DIAG1[i-1][j-1] + val[i][j];
if(i!=0) DIAG2[i][j] = DIAG2[i-1][j+1] + val[i][j];
if(j!=0) WE[i][j] = WE[i][j-1] + val[i][j];
if(i!=0) NS[i][j] = NS[i-1][j] + val[i][j];
}
}
finish_QUAD0(); finish_QUAD1(); finish_QUAD2(); finish_QUAD3();
for(i=1 ; i<=K ; i++)
{
for(j=1 ; j<=K ; j++)
{
ll dist = abs(i-1) + abs(j-1);
if(dist <= K-1) CALC[1][1] += (K - dist) * val[i][j];
}
}
for(i=1 ; i<=N+2*K ; i++)
{
for(j=1 ; j<=N+2*K ; j++)
{
if(i == 1 && j == 1) continue;
if(j == 1) // get from top
{
CALC[i][j] = CALC[i-1][j];
CALC[i][j] += (QUAD[2][i][j] + QUAD[3][i][j] - NS_p(i+K-1, i-1, j));
CALC[i][j] -= (QUAD[0][i-1][j] + QUAD[1][i-1][j] - NS_p(i-1, i-K-1, j));
}
else // get from left
{
CALC[i][j] = CALC[i][j-1];
CALC[i][j] += (QUAD[0][i][j] + QUAD[3][i][j] - WE_p(i, j+K-1, j-1));
CALC[i][j] -= (QUAD[1][i][j-1] + QUAD[2][i][j-1] - WE_p(i, j-1, j-K-1));
}
}
}
ll ans = 0;
for(i=1 ; i<=N+2*K ; i++)
for(j=1 ; j<=N+2*K ; j++)
ans = max(ans, CALC[i][j]);
cout << ans << endl;
}
int main(void)
{
fio; ll i, tc; cin >> tc;
for(i=1 ; i<=tc ; i++)
{
cout << "Case #" << i << endl;
solve(); // endl in solve
}
return 0;
}
|
cs |
4번 : 패턴 매칭
부분문제 2까지는 최근 IOI 선발고사에서 나온 문제와 같고, 이 아이디어를 확장하면 문제를 해결할 수 있다.
저 동치 조건을 깔끔하게 나타낼 방법을 찾는 것이 이 문제를 해결하는 핵심이다.
결론부터 말하자면, 각 문자열의 각 문자에 대해서 "마지막으로 그 문자가 나온 위치까지의 거리"를 생각하면 동치 조건이 깔끔해진다. 예를 들어,
superguesser의 경우 순서대로 마지막으로 그 문자가 나온 위치까지 거리가 -1, -1, -1, -1, -1, -1, 5, 4, 8, 1, 3, 7가 된다.
abcdefbdaade도 역시 순서대로 마지막으로 그 문자가 나온 위치까지 거리가 -1, -1, -1, -1, -1, -1, 5, 4, 8, 1, 3, 7가 된다.
단, -1은 이전에 그 문자가 나오지 않았음을 의미한다.
또한, 이 두 문자열은 동치임을 직접 확인할 수 있으며, 일반적으로도 이렇게 두 문자열의 동치 여부를 확인할 수 있음을 증명할 수 있다.
이제 가장 "자연스러운" 접근은, 문자열을 위와 같이 숫자 형태로 전환시킨 다음, KMP를 쓰는 것이다.
이 접근은 다 좋은데, -1을 처리하는 것에 약간의 신경을 써야 한다. 예를 들어, KMP를 쓰면 기본적으로 하는 접근이 $[i-fail[i]+1, i]$가 전체 문자열의 prefix와 같다는 것이다. 여기서 다음 문자를 확인하여 이 prefix를 연장시킬 수 있는지 확인해야 한다. 만약 실제 prefix에서 $fail[i]$번째 문자에 대응되는 값이 -1이라면, 이는 이 문자가 prefix에서 지금까지 등장하지 않은 문자임을 의미한다. 이를 확인하기 위해서는 단순히 $i+1$번째 문자에 대응되는 값이 -1임을 확인하면 안되고, 그 값이 -1이거나 $fail[i]$를 초과하는지 확인해야 한다. 즉, KMP에서 지금 확인하고 있는 suffix의 범위를 넘어가는 경우를 역시 고려해주어야 한다.
여기까지 생각하면 KMP 코드를 거의 그대로 가져와서 부분문제 2까지 해결할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
#include <bits/stdc++.h>
#define fio ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
using namespace std;
typedef long long int ll;
typedef unsigned long long int ull;
typedef long double ldb;
const ll mod = 1e9 + 7;
string s; ll N, K;
string pat[31111];
ll pogs[2222222];
ll fail[511], pog[511];
ll rec_s[26], rec_p[26];
void precompute(void)
{
ll i;
for(i=0 ; i<26 ; i++) rec_s[i] = -1;
for(i=0 ; i<s.length() ; i++)
{
int cur = s[i] - 'a';
if(rec_s[cur] == -1) pogs[i] = -1;
else pogs[i] = i - rec_s[cur];
rec_s[cur] = i;
}
}
ll calc(ll idx)
{
ll i, j=0;
for(i=0 ; i<26 ; i++) rec_p[i] = -1;
memset(fail, 0, sizeof(fail));
for(i=0 ; i<pat[idx].length() ; i++)
{
int cur = pat[idx][i] - 'a';
if(rec_p[cur] == -1) pog[i] = -1;
else pog[i] = i - rec_p[cur];
rec_p[cur] = i;
}
for(i=1 ; i<pat[idx].length() ; i++)
{
while(1)
{
if(j == 0) break;
if(pog[i] == pog[j]) break;
if(pog[j] == -1 && pog[i] > j) break;
j = fail[j-1];
}
if((pog[i] == pog[j]) || (pog[j] == -1 && pog[i] > j)) fail[i]=++j;
}
ll ret=0; j=0;
for(i=0 ; i<s.length() ; i++)
{
while(j>0 && !(pogs[i] == pog[j] || (pog[j] == -1 && pogs[i] > j))) j=fail[j-1];
if((pogs[i] == pog[j]) || (pog[j] == -1 && pogs[i] > j))
{
if(j==pat[idx].length()-1) { ret++; j=fail[j]; }
else j++;
}
}
return ret;
}
void solve(void)
{
cin >> N >> K; ll i, ans = 0; cin >> s; precompute();
for(i=1 ; i<=K ; i++) cin >> pat[i];
for(i=1 ; i<=K ; i++) ans += i * calc(i);
cout << ans << endl;
}
int main(void)
{
fio; ll i, tc; cin >> tc;
for(i=1 ; i<=tc ; i++)
{
cout << "Case #" << i << endl;
solve(); // endl in solve
}
return 0;
}
|
cs |
이제 패턴이 여러 개 존재하니, KMP를 Aho-Corasick으로 바꾸어주면 된다. Trie의 각 노드에는
- 기본적인 정보인 failure link, output link, count, 끝 정점인지 여부
- 현재 보고 있는 문자열의 길이 (-1을 처리하기 위함이다)
- 그리고 각 경우에 대응되는 다음 노드의 포인터
를 저장한다. 이때, 다음 노드를 확인하기 위해 사용하는 것은 알파벳 자체가 아니라 해당 알파벳의 마지막 등장 위치까지의 거리다.
각 노드에 저장되어 있는 문자열의 길이 정보에 따라서, 내가 -1을 사용해야 하는지 실제 등장 위치까지의 거리를 사용해야 하는지가 달라진다.
위 KMP 풀이와 Aho-Corasick 알고리즘을 잘 이해하고 있다면, 풀이를 변형하는 것은 어렵지 않다. 코드는 https://blog.myungwoo.kr/101를 참고했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
|
#include <bits/stdc++.h>
#define fio ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
using namespace std;
typedef long long int ll;
typedef unsigned long long int ull;
typedef long double ldb;
const ll mod = 1e9 + 7;
string s; ll N, K;
string pat[31111];
struct Trie
{
map<ll, Trie*> S;
Trie* fail;
Trie* output;
ll cur_len;
ll count; bool is_end;
Trie() { S.clear(); fail=nullptr; output=nullptr; count=0; cur_len=0; is_end=false; }
~Trie() { S.clear(); }
};
Trie* end_node[31111];
queue<Trie*> Q;
vector<Trie*> ord;
ll rec_p[26], rec_s[26];
ll pog[31111], pogs[2222222];
map<ll, Trie*>::iterator it;
void solve(void)
{
ord.clear(); cin >> N >> K; ll i, j, ans = 0; cin >> s;
memset(pog, 0, sizeof(pog));
memset(pogs, 0, sizeof(pogs));
for(i=1 ; i<=K ; i++) cin >> pat[i];
Trie *root = new Trie;
// Step 1 : Build the Trie
for(i=1 ; i<=K ; i++)
{
Trie *now = root;
for(j=0 ; j<26 ; j++) rec_p[j] = -1;
for(j=0 ; j<pat[i].length() ; j++)
{
int cur = pat[i][j] - 'a';
if(rec_p[cur] == -1) pog[j] = -1;
else pog[j] = j - rec_p[cur];
rec_p[cur] = j;
}
for(j=0 ; j<pat[i].length() ; j++)
{
if(now->S.find(pog[j]) == now->S.end()) {
now->S[pog[j]] = new Trie;
}
now->S[pog[j]]->cur_len = now->cur_len + 1;
now = now->S[pog[j]];
}
now->is_end = true;
end_node[i] = now;
}
// Queue Setup
for(it = root->S.begin() ; it != root->S.end() ; it++) {
it->second->fail = root;
Q.push(it->second);
}
// Fail Setup
while(!Q.empty())
{
Trie *cur = Q.front(); Q.pop();
if(cur->is_end) cur->output = cur;
else cur->output = cur->fail->output;
for(it = cur->S.begin() ; it != cur->S.end() ; it++) {
ll cur_step = it->first;
Trie *nxt = it->second;
nxt->fail = cur->fail;
while(1)
{
if(nxt->fail == root) break;
ll len = nxt->fail->cur_len;
ll true_step = cur_step;
if(true_step > len) true_step = -1;
if(nxt->fail->S.find(true_step) != nxt->fail->S.end()) break;
nxt->fail = nxt->fail->fail;
}
ll true_step = cur_step;
ll len = nxt->fail->cur_len;
if(true_step > len) true_step = -1;
if(nxt->fail->S.find(true_step) != nxt->fail->S.end())
nxt->fail = nxt->fail->S[true_step];
Q.push(nxt);
}
}
// start finding
Trie *now = root;
for(i=0 ; i<26 ; i++) rec_s[i] = -1;
for(i=0 ; i<s.length() ; i++)
{
int cur = s[i] - 'a';
if(rec_s[cur] == -1) pogs[i] = -1;
else pogs[i] = i - rec_s[cur];
rec_s[cur] = i;
}
for(i=0 ; i<s.length() ; i++)
{
ll cur_step = pogs[i];
while(1)
{
if(now == root) break;
ll true_step = cur_step;
if(true_step > now->cur_len) true_step = -1;
if(now->S.find(true_step) != now->S.end()) break;
now = now->fail;
}
ll true_step = cur_step;
if(true_step > now->cur_len) true_step = -1;
if(now->S.find(true_step) != now->S.end()) now=now->S[true_step];
if(now->output) now->output->count++;
}
// finish
Q.push(root);
while(!Q.empty())
{
Trie *cur=Q.front(); Q.pop();
ord.push_back(cur);
for(it = cur->S.begin() ; it != cur->S.end() ; it++) Q.push(it->second);
}
reverse(ord.begin(), ord.end());
for(i=0 ; i<ord.size() ; i++)
if(ord[i]->is_end && ord[i]->fail->output)
ord[i]->fail->output->count+=ord[i]->count;
for(i=1 ; i<=K ; i++) ans += i * end_node[i]->count;
delete root;
cout << ans << endl;
}
int main(void)
{
fio; ll i, tc; cin >> tc;
for(i=1 ; i<=tc ; i++)
{
cout << "Case #" << i << endl;
solve(); // endl in solve
}
return 0;
}
|
cs |
'PS > 대회 후기' 카테고리의 다른 글
| SCPC 2021 1차 예선 풀이 (0) | 2021.07.16 |
|---|---|
| ACM-ICPC Seoul Regional 2020 (0) | 2020.11.20 |
| SCPC 2020 본선 후기 (5) | 2020.11.09 |
| ACM-ICPC Seoul Regional Preliminary 2020 (0) | 2020.10.19 |
| SCPC 2020 2차 예선 풀이 (1) | 2020.09.05 |