Introduction
I participated in the first cohort of the Axiom Open Source Program. After studying and being fascintated with the theory of ZK-friendly hashes, I decided that I will implement some of them for this program. My target for implementation was the newly (at the time) developed Poseidon2 hash function. After a while, I kept thinking about what to do next, whether to keep implementing more hashes or go in a different direction. At this point, my friend asked me about a interesting puzzle, and it went like this.
Suppose a password-based key management system stores the user's key as $E(pw, K)$. Suppose the user now wants to change the password into $pw'$, so the storage should change to $E(pw', K)$. How should the system verify that this new value is still an encryption of $K$, without knowing $pw, pw', K$ at all?
This was a very interesting and real-world puzzle - and some search lead to the theory of verifiable encryption, where a certain property is proved over an encrypted plaintext. It's also clear that ZKP can give us a solution here.
By allowing the system to store $Hash(K)$, we can change this problem to
Prove that the user knows $pw, K$ such that $Hash(K) = A$ and $E(pw, K) = B$ where $A, B$ are stored on the system.
Selecting the hash function as Poseidon2, I was left with selecting $E$ - and I decided for AES. For simplicity, I chose AES-ECB.
I also decided that I will try to use pure halo2-lib as much as possible - this is because I already implemented Poseidon2 in halo2-lib at the time, and mixing vanilla halo2 with Axiom's halo2-lib is definitely not an easy task.
Implementing Poseidon2
To discuss the implementation aspects of Poseidon2, we need to first how Poseidon and Poseidon2 works.
Roughly speaking, these two hash functions are based on a sponge-based construction, which means that the hash is based on a permutation. Poseidon hash has a width parameter $t$, and this means that the permutation is of $\mathbb{F}_p^t \rightarrow \mathbb{F}_p^t$. To design this permutation, Poseidon uses three types of layers - round constant addition, MDS matrix linear layer, and the SBOX layer.
The round constant addition layer is straightforward - it simply adds a round constant to each element.
The MDS matrix linear layer is also straightforward - it's a matrix multiplication. The "MDS" part is a description about the matrix which is needed for security analysis, but for implementation/understanding purposes it's not very important.
The SBOX layer is $S(x) = x^\alpha$, where $\alpha$ is the minimum positive integer that $\gcd(\alpha, p - 1) = 1$. For BN254, we select $\alpha = 5$.
The most interesting part of Poseidon is the difference of full rounds and partial rounds. The idea is that not all the rounds needs to have S-boxes to every element in the state. Instead, we can use partial rounds, which only uses the S-box for a single element in the state. By putting $R_f = R_F / 2$ full rounds, then $R_P$ partial rounds, then $R_f = R_F / 2$ full rounds, we can maintain security while saving the use of many S-boxes, leading to a more efficient hash function. The outline of this permutation is shown in a figure below.

So what's the difference between Poseidon and Poseidon2? There are some subtle differences, but the main difference lies in the difference in the MDS matrix linear layer. The matrices are generated differently, for better native runtime and better costs in terms the ZKP. The matrix for the external full rounds and the internal partial rounds is also different. This permutation's layout is shown in the figure below.

As Poseidon is already implemented in Axiom's halo2-lib, all I needed to do was implement these differences.
Grain LFSR & The Parameter Generation
The first part is the parameter generation algorithm. For Poseidon, this is implemented in halo2/primitives/poseidon.
The parameters for the round constants or the matrix multiplication is generated based on Grain LFSR, and the initial values for this LFSR is with basic parameters such as $R_F, R_P$. Due to the different matrix format between Poseidon and Poseidon2, the generation algorithm itself is also quite different. I implemented the same algorithm from the Horizen Labs implementation, in their repository.
There is one interesting part of the matrix generation algorithm that is common in both Poseidon and Poseidon2, which is the testing for the so called invariant subspace trails. The details for why this is important and how to test for it is beyond the scope of this blog post, but interested readers should dive into the literature of cryptanalysis on Poseidon. Anyways, what this means is that sometimes we need to re-generate the matrices if the generated matrix fails this check. However, implementing this in rust is quite time consuming as it deals with the computation of minimal polynomials of matrices. Therefore, I hardcoded the number of tries it takes to reach a matrix that satisfies the necessary checks. The unfortunate consequence is that this makes the implementation not fully generic, as it assumes that the field we are working on is over BN254. If there is a rust library for minimal polynomials of matrices, this can be written to be generic over any prime field.
Implementation of Matrix Layers
While there are many optimization tricks in Poseidon, many of them are not relevant in Poseidon2. The main trick in Poseidon2 is that the matrices are designed to be easy to multiply, both in native computation and in the ZKP world. The overall implementation strategy was taken from the Horizen Labs implementation. These strategies are also described in the Poseidon2 paper's Appedix as well.
The main operation used to implement these matrix layers is mul_add in the `GateInstructions`.

Interesting Issues on the Horizen Labs Implementation
During the implementation process, I found some very interesting issues/points on the Horizen Labs implementation. This is quite awkward, as the Horizen Labs implementation is the reference implementation after all, and it is the implementation that is mentioned in the Poseidon2 paper itself. Therefore, the questions I will mention below may surve little to no purpose. With that in mind, here they are.
The first one is the Grain LFSR parameters. In the Poseidon parameter generation, the SBOX parameter is selected as 0 if the SBOX is of $x^\alpha$ with small positive $\alpha$ and 1 if the SBOX is $x^{-1}$. In the Poseidon2 parameter generation, it's the opposite - the SBOX parameter is 1.
The second one is in the plain implementation itself. In the Poseidon2 parameter generation, it's clear that the external matrix in the case $t = 4$ is simply $M_4$. However, in the plain implementation itself, it uses $2M_4$ as the external matrix. This is caused because the matrix for $t = 4t'$ with $t' \ge 2$ is with a circulant matrix $circ(2M_4, M_4, \cdots , M_4)$, and the implementation forgot to handle the case $t = 4$.
This issue is now fixed on the Poseidon2 repository.
Implementing AES
AES-ECB is, well, AES-ECB. If you look at some pure python implementations like this one, we see that we need to implement the SBOX, the byte xor operations, the "xtime" operation, and the byte range check. The remainder will be straightforward implementation.
Implementing the SBOX
There are three ways to proceed here.
- Use a lookup table of size $2^8$
- Create a SBOX table as a witness, then use Axiom's "select_from_idx"
- Implement the $GF(2^8)$ arithmetic and the affine transformation on $\mathbb{F}_2^8$
The third option seemed to be way too complex, so initial implementation used the second option. However, as you can expect, this is very inefficient, so a lookup table had to be used. The issue is that using pure Axiom halo2-lib and using lookup tables at the same time is quite non-trivial, especially if there are multiple tables to be used. To use a lookup table, I used the methodology from the RangeChip and the RangeCircuitBuilder - practically copy pasting everything except for the actual lookup table part. I added 0 and $256 \cdot (x + 1) + S(x)$ to the lookup table. Then, I could claim that $y = S(x)$ if $x, y$ are all within $[0, 256)$ and $256 \cdot (x + 1) + y \in T$.

Implementing Byte XORs and "xtime"
There are two ways to continue here.
- Again, use a lookup table
- Decompose everything as bits, then use bit XORs to implement byte operations
At first, I implemented in the second way. A bit xor can be implemented with a not gate and a select gate.
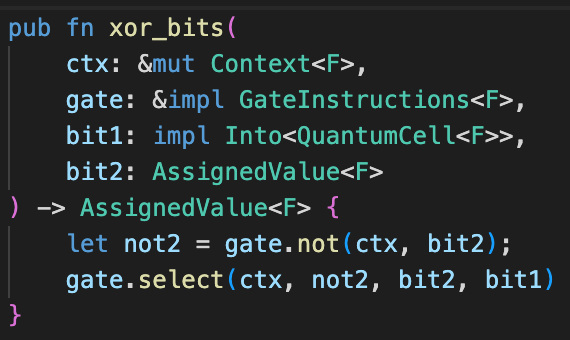
However, I turned to using a lookup table in hopes of optimizing the circuit. I added $2^{24} + 2^{16} \cdot a + 2^8 \cdot b + a \oplus b$ to the lookup table - and with the assumption that $a, b, c \in [0, 256)$, $2^{24} + 2^{16} \cdot a + 2^8 \cdot b + c \in T$ is enough to force $c = a \oplus b$.
The same goes for the xtime operation. I added $2^{25} + 2^8 \cdot x + xtime(x)$ to the lookup table, and with the assumption that $a, b \in [0, 256)$, $2^{25} + 2^8 \cdot a + b \in T$ is enough to force $b = xtime(a)$.
Implementing the Byte Range Check
There are two ways to proceed here.
- Use a lookup table
- Decompose the byte to 8 bits
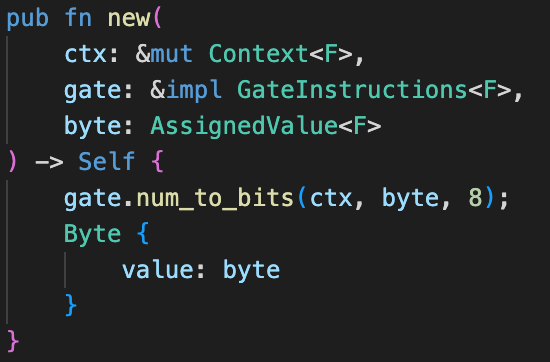
The issue with the first approach is that we are currently using a single lookup table. Also, many checks with the lookup table so far is built on the assumption that every value is within $[0, 256)$. Therefore, performing byte checks with a lookup table (unless we somehow manage to use multiple lookup tables) leads to the danger of circular reasoning. I simply used the num_to_bits function of Axiom's halo2-lib to check that the values are within 8 bits. This is indeed quite a bit costly, and is the main further optimization that could be done.
Final Benchmarks

Taken directly from the final presentation, we see that Poseidon2 is better in ZKP terms when the width $t$ is large. This is natural, as Poseidon2's dominant performance usually comes in native calculation, and the ZKP cost gets better when $t$ is large and the MDS matrices' special forms become more and more helpful in decreasing the cost. In a way, this benchmark agrees with the paper.
In AES, we see that a single block costs around 66k cells in AES128, so around 6k per single AES round.
If we can make multiple lookup tables possible, we can remove the 8 bit decomposition check, and get better performance.
'Cryptography' 카테고리의 다른 글
| Brakedown Overview (0) | 2023.10.13 |
|---|---|
| Monolith Hash Function (0) | 2023.09.30 |
| ZK Applications (0) | 2023.03.03 |
| Polynomials and Elliptic Curves in ZK (0) | 2023.02.27 |
| A Hyperelliptic Curve Story (0) | 2023.02.22 |