이어서 간다. 이번 글에서 다룰 주제는
- OSPEP를 이용한 DRS의 tight contraction factor
- OSPEP를 이용한 optimal parameter selection
- CVXPY를 이용한 위 주제들과 관련된 구현 몇 가지
Part 3. Tight Analytic Contraction Factors for DRS
결과부터 소개한다. 우리가 앞에서 준비했던, 논문의 정리 4.1.만 소개한다. 그래도 논문 링크를 열고 정리 4.1.~4.4.를 한 번 확인하는 것을 추천.

결과도 매우 중요하지만, 아무래도 일단 관심이 가는 것은 대체 이렇게 복잡한 것을 어떻게 증명했냐는 것이다. 논문의 말을 옮기면,
- 기본적으로 Mathematica 같은 Computer Algebra System은 필요하다
- OSPEP에서 얻은 Primal/Dual Problem을 활용한다. 이들을 풀기 위해서, 다음과 같은 접근을 사용한다.
- Primal : 핵심 아이디어는 worst-case operator가 $\mathbb{R}^2$ 위에서 존재할 것이라는 추측이다. 이는 Primal Problem의 해 $G^{*}$의 rank가 2 이하라는 것과 동치인데, 이 추측의 근거는 complementary slackness라고 한다. 이러한 2차원 위에서의 worst-case analysis는 SDP 대신 non-convex quadratic programming 문제로 분석할 수 있고, 이 문제에 대응되는 Karush–Kuhn–Tucker condition을 이용하여 문제를 해결했다고 한다.
- Dual : 역시 여기서도 Dual Problem의 해로 얻어지는 행렬 $S^{*}$가 rank 2 이하라는 가정을 한다. 근거는 Primal과 동일하다. 이 가정으로 $\rho^2$과 $\lambda_\mu^A$, $\lambda_\beta^B$ 사이의 관계식을 추가적으로 얻고, 이를 constraint로 하여 $\rho^2$을 최소화했다고 한다. 말이 쉽지만 정말 어려워 보인다..
- 이렇게 Primal/Dual 문제를 (analytical) 푼 다음, 그 결과가 같음을 확인하면 자동으로 증명이 끝난다.
Appendix를 구경하면 이 결과의 엄밀한 증명을 직접 볼 수 있다. ㄹㅇ 가슴이 웅장해진다...
Part 4 : Optimal Parameter Selection with OSPEP
여기서는 operator class $\mathcal{Q}_1$, $\mathcal{Q}_2$를 알고 있을 때 parameter $\alpha, \theta$를 optimal 하게 설정하는 방법을 다룬다.
이는 결국 $\rho^2_{*} (\alpha, \theta)$를 해당 $\alpha, \theta$에 대한 optimal contraction factor라고 할 때, $$\rho^2_{*} = \inf_{\alpha, \theta > 0} \rho^2_{*}(\alpha, \theta)$$와 대응되는 $\alpha_{*}$, $\theta_{*}$를 찾는 문제와 같다. 원래 $\theta \in (0, 2)$라는 조건이 있으나, 이 조건은 relax 해도 무방하다.
$\rho^2_{*}(\alpha, \theta)$의 값 자체는 SDP를 풀어서 계산할 수 있으니, 이차원 위에서 미분 불가능한 함수를 최소화하는 일반적인 알고리즘이 있다면 이를 사용하여 문제를 해결할 수도 있을 것이다. 그러나, 조금 더 작업을 거치면 더욱 편하게 문제를 풀 수 있다. $\theta$를 최적화 문제 안에 집어넣자.
Dual Problem $$\begin{equation*} \begin{aligned} \text{minimize} \quad & \rho^2 \\ \text{subject to} \quad & \lambda_\mu^A, \lambda_\beta^B \ge 0 \\ \quad & S = -M_O - \lambda_\mu^A M_\mu^A - \lambda_\beta^B M_{\beta}^B + \rho^2 M_I \succeq 0 \end{aligned} \end{equation*}$$을 다시 생각해보자. 우리가 $\alpha, \theta$를 고정된 값이 아니라 최적화 문제의 변수로 두지 못하는 이유는, 행렬 $S$의 entry가 $\alpha, \theta$의 nonlinear term을 포함하고 있기 때문이다. $\alpha$는 아예 분모에 있고, $\theta$는 $\theta^2$ 항이 $S$에 있다. 여기서 $\theta$에 대한 quadratic term을 제거하기 위해, Schur Complement를 사용한다.
$$\begin{equation*} \begin{aligned} S &= -M_O - \lambda_\mu^A M_\mu^A - \lambda_\beta^B M_{\beta}^B + \rho^2 M_I \\ S' &= - \lambda_\mu^A M_\mu^A - \lambda_\beta^B M_{\beta}^B + \rho^2 M_I \end{aligned} \end{equation*} $$라고 정의하면, $$M_O = (1, \theta, -\theta)^T (1, \theta, -\theta)$$이므로, Schur Complement의 성질에서 $S \succeq 0$는 $v = (1, \theta, -\theta)^T$라 했을 때 $$\overline{S} = \left[ \begin{matrix} S' & v \\ v^T & 1 \end{matrix} \right] \succeq 0$$과 동치이다. 또한, $S'$은 각 entry에 $\theta$에 대한 non-linear term이 없으므로, $\theta$까지 SDP에 넣을 수 있다.
즉, 새로운 문제를 $$\begin{equation*} \begin{aligned} \text{minimize} \quad & \rho^2 \\ \text{subject to} \quad & \lambda_\mu^A, \lambda_\beta^B, \theta \ge 0 \\ \quad & S' = - \lambda_\mu^A M_\mu^A - \lambda_\beta^B M_{\beta}^B + \rho^2 M_I \\ \quad & v = (1, \theta, -\theta)^T \\ \quad & \overline{S} = \left[ \begin{matrix} S' & v \\ v^T & 1 \end{matrix} \right] \succeq 0 \end{aligned} \end{equation*}$$로 바꾸면, $\theta$에 대한 최적화까지 자동으로 된다. 이제 남은 것은 $\alpha$에 대한 최적화다.
이렇게 해서 얻은 주어진 $\alpha$에 대한 optimal contraction factor를 $\rho^2_{*}(\alpha)$라고 하자. 이를 최소화하면 된다.
변수 하나에 대한 (미분 불가능한) 함수의 minimization은 다양한 방법이 있다. 그런데, 실험 결과에 따르면
- 함수 $\rho^2_{*}(\alpha)$는 연속함수이다. (별로 놀랍지는 않은 사실)
- 함수 $\rho^2_{*}(\alpha)$는 unimodal 함수이다. (놀라운 사실)
그러므로, 이를 최소화하기 위해서 (PS를 했던 사람의 입장에서 쉽게 생각하면) 삼분탐색을 사용해도 좋다.
사실 scipy나 matlab 등에서 이미 derivative-free optimization이 구현이 되어있기 때문에, 이걸 가져다 쓰면 된다.
Part 5 : Programming OSPEP with CVXPY
이건 논문에는 없고 (정확하게는 CVXPY로 하지 않고 MATLAB 등으로 한 것 같다) 그냥 내가 심심해서 하는 것이다.
논문의 저자들이 사용한 코드를 보고 싶다면, github.com/AdrienTaylor/OperatorSplittingPerformanceEstimation로 가자.
내가 여기서 짠 코드들은 github.com/rkm0959/rkm0959_implements에 가면 있다.
Task 1 : Verifying Theorem 4.1. Numerically
CVXPY를 이용하여 Theorem 4.1.을 검증해보자. 방법은 다음과 같다.
- $\alpha, \theta, \mu, \beta$를 적당히 랜덤하게 선정한다.
- 대응되는 Primal/Dual Problem을 CVXPY로 해결한다. SDP를 풀어야하니, blas+lapack을 설치해야 한다.
- 또한, Theorem 4.1.을 이용하여 optimal contraction factor를 계산한다.
- Theorem 4.1.에는 Case가 총 5가지가 있다. 이때, 어떤 Case에서 계산이 되었는지도 기록한다.
- Primal Problem, Dual Problem, Theorem 4.1.로 얻은 답이 일치하는지 확인한다.
- 위 과정을 여러 번 반복한 후, 5가지의 Case를 각각 몇 번 다루었는지를 확인한다.
이를 구현한 코드는 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
|
import cvxpy as cp
import matplotlib.pyplot as plt
import numpy as np
import math
def THM_4_1_scaled(theta, mu, beta):
assert 0 < theta < 2 and mu > 0 and beta > 0
if mu * beta - mu + beta < 0 and theta <= 2 * (beta + 1) * (mu - beta - mu * beta) / (mu + mu * beta - beta - beta * beta - 2 * mu * beta * beta):
return 1, abs(1 - theta * beta / (beta + 1))
if mu * beta - mu - beta > 0 and theta <= 2 * (mu * mu + beta * beta + mu * beta + mu + beta - mu * mu * beta * beta) / (mu * mu + beta * beta + mu * mu * beta + mu * beta * beta + mu + beta - 2 * mu * mu * beta * beta):
return 2, abs(1 - theta * (1 + mu * beta) / (1 + mu) / (1 + beta))
if theta >= 2 * (mu * beta + mu + beta) / (2 * mu * beta + mu + beta):
return 3, abs(1 - theta)
if mu * beta + mu - beta < 0 and theta <= 2 * (mu + 1) * (beta - mu - mu * beta) / (beta + mu * beta - mu - mu * mu - 2 * mu * mu * beta):
return 4, abs(1 - theta * mu / (mu + 1))
ret = (2 - theta) / 4
ret = ret * ((2 - theta) * mu * (beta + 1) + theta * beta * (1 - mu))
ret = ret * ((2 - theta) * beta * (mu + 1) + theta * mu * (1 - beta))
ret = ret / mu / beta
ret = ret / (2 * mu * beta * (1 - theta) + (2 - theta) * (mu + beta + 1))
return 5, math.sqrt(ret)
def THM_4_1_unscaled(alpha, theta, mu, beta):
return THM_4_1_scaled(theta, mu * alpha, beta / alpha)
def gen_M_O(theta):
ret = [[1, theta, -theta],
[theta, theta * theta, -theta * theta],
[-theta, -theta * theta, theta * theta]]
return np.array(ret)
def gen_M_I():
ret = np.zeros((3, 3))
ret[0, 0] = 1
return ret
def gen_M_mu_A(alpha, mu):
ret = [[0, -1/2, 0],
[-1/2, -(1+alpha*mu), 1],
[0, 1, 0]]
return np.array(ret)
def gen_M_beta_B(alpha, beta):
ret = [[-beta/alpha, 0, beta/alpha + 1/2],
[0, 0, 0],
[beta/alpha + 1/2, 0, -beta/alpha-1]]
return np.array(ret)
def Primal(alpha, theta, mu, beta):
G = cp.Variable((3, 3), symmetric = True)
M_O = gen_M_O(theta)
M_I = gen_M_I()
M_mu_A = gen_M_mu_A(alpha, mu)
M_beta_B = gen_M_beta_B(alpha, beta)
constraints = []
constraints.append(G >> 0)
constraints.append(cp.trace(M_I @ G) == 1)
constraints.append(cp.trace(M_mu_A @ G) >= 0)
constraints.append(cp.trace(M_beta_B @ G) >= 0)
objective = cp.Maximize(cp.trace(M_O @ G))
problem = cp.Problem(objective, constraints)
problem.solve()
return math.sqrt(problem.value)
def Dual(alpha, theta, mu, beta):
lambda_mu_A = cp.Variable()
lambda_beta_B = cp.Variable()
rho_sq = cp.Variable()
M_O = gen_M_O(theta)
M_I = gen_M_I()
M_mu_A = gen_M_mu_A(alpha, mu)
M_beta_B = gen_M_beta_B(alpha, beta)
constraints = []
constraints.append(lambda_mu_A >= 0)
constraints.append(lambda_beta_B >= 0)
constraints.append(-M_O - lambda_mu_A * M_mu_A - lambda_beta_B * M_beta_B + rho_sq * M_I >> 0)
objective = cp.Minimize(rho_sq)
problem = cp.Problem(objective, constraints)
problem.solve()
return math.sqrt(problem.value)
eps = 0.0005
checked = [0, 0, 0, 0, 0]
for _ in range(300):
alpha = np.random.uniform(low = 0.5, high = 2.0)
theta = np.random.uniform(low = 0.05, high = 1.95)
mu = np.random.uniform(low = 0.1, high = 3.9)
beta = np.random.uniform(low = 0.1, high = 3.9)
assert alpha > 0 and theta > 0
assert mu > 0 and beta > 0
val_1 = Primal(alpha, theta, mu, beta)
val_2 = Dual(alpha, theta, mu, beta)
whi, val_3 = THM_4_1_unscaled(alpha, theta, mu, beta)
checked[whi - 1] += 1
if abs(val_2 - val_1) > eps or abs(val_3 - val_1) > eps or abs(val_3 - val_2) > eps:
print(val_1, val_2, val_3)
print("Failed at Case", whi)
print("Parameters:", alpha, theta, mu, beta)
break
print("Checked Cases")
for i in range(5):
print("Case #{} Verified {} Times!".format(i + 1, checked[i]))
print("Finished!")
|
cs |
이렇게 하여 Theorem 4.1.의 결과를 검수할 수 있다. SDP solver가 문제를 잘 해결할 수 있도록 극단적인 값들은 넣지 않았다.
각 코드의 의미는 거의 자명하니 (식을 그대로 옮긴 것에 불과하다) 자세한 설명은 생략하도록 하겠다. Task 1은 이렇게 끝.
Task 2 : Optimal Parameter Selection with OSPEP
이번에는 Part 4에서 다루었던 내용을 구현해보자. 우리가 할 일은
- 주어진 $\mu, \beta$에 대하여 optimal parameter $\alpha, \theta$를 계산
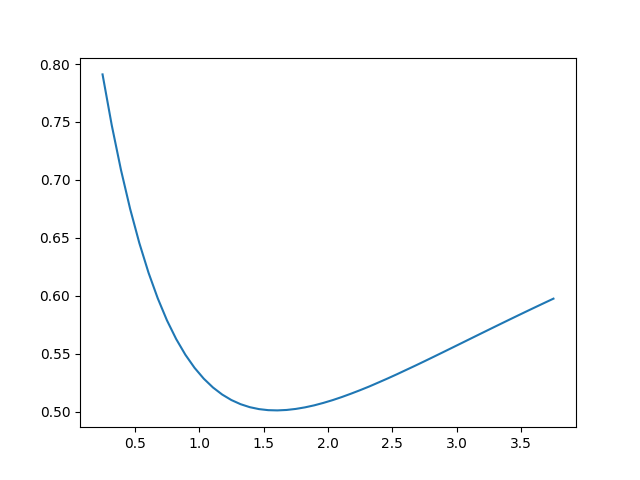
- $\rho^2_{*} (\alpha)$의 그래프를 그리고, 실제로 unimodal function인지 눈으로 확인
- 물론, 이러한 내용 및 그래프는 논문에도 있으며, DRS가 아니라 DYS로 설명되어 있다.
Part 4의 내용을 그대로 CVXPY로 옮기면, 다음과 같은 코드를 얻을 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
|
import cvxpy as cp
import matplotlib.pyplot as plt
import numpy as np
import math
def THM_4_1_scaled(theta, mu, beta):
assert 0 < theta < 2 and mu > 0 and beta > 0
if mu * beta - mu + beta < 0 and theta <= 2 * (beta + 1) * (mu - beta - mu * beta) / (mu + mu * beta - beta - beta * beta - 2 * mu * beta * beta):
return 1, abs(1 - theta * beta / (beta + 1))
if mu * beta - mu - beta > 0 and theta <= 2 * (mu * mu + beta * beta + mu * beta + mu + beta - mu * mu * beta * beta) / (mu * mu + beta * beta + mu * mu * beta + mu * beta * beta + mu + beta - 2 * mu * mu * beta * beta):
return 2, abs(1 - theta * (1 + mu * beta) / (1 + mu) / (1 + beta))
if theta >= 2 * (mu * beta + mu + beta) / (2 * mu * beta + mu + beta):
return 3, abs(1 - theta)
if mu * beta + mu - beta < 0 and theta <= 2 * (mu + 1) * (beta - mu - mu * beta) / (beta + mu * beta - mu - mu * mu - 2 * mu * mu * beta):
return 4, abs(1 - theta * mu / (mu + 1))
ret = (2 - theta) / 4
ret = ret * ((2 - theta) * mu * (beta + 1) + theta * beta * (1 - mu))
ret = ret * ((2 - theta) * beta * (mu + 1) + theta * mu * (1 - beta))
ret = ret / mu / beta
ret = ret / (2 * mu * beta * (1 - theta) + (2 - theta) * (mu + beta + 1))
return 5, math.sqrt(ret)
def THM_4_1_unscaled(alpha, theta, mu, beta):
return THM_4_1_scaled(theta, mu * alpha, beta / alpha)
def gen_Base():
ret = np.zeros((4, 4))
ret[0, 3] = 1
ret[3, 0] = 1
ret[3, 3] = 1
return ret
def gen_M_theta():
ret = np.zeros((4, 4))
ret[1, 3] = 1
ret[2, 3] = -1
ret[3, 1] = 1
ret[3, 2] = -1
return ret
def gen_M_I():
ret = np.zeros((4, 4))
ret[0, 0] = 1
return ret
def gen_M_mu_A(alpha, mu):
ret = [[0, -1/2, 0, 0],
[-1/2, -(1+alpha*mu), 1, 0],
[0, 1, 0, 0],
[0, 0, 0, 0]]
return np.array(ret)
def gen_M_beta_B(alpha, beta):
ret = [[-beta/alpha, 0, beta/alpha + 1/2, 0],
[0, 0, 0, 0],
[beta/alpha + 1/2, 0, -beta/alpha-1, 0],
[0, 0, 0, 0]]
return np.array(ret)
def opt_val(alpha, mu, beta, retrieve = False):
lambda_mu_A = cp.Variable()
lambda_beta_B = cp.Variable()
theta = cp.Variable()
rho_sq = cp.Variable()
Base = gen_Base()
M_theta = gen_M_theta()
M_I = gen_M_I()
M_mu_A = gen_M_mu_A(alpha, mu)
M_beta_B = gen_M_beta_B(alpha, beta)
constraints = []
constraints.append(lambda_mu_A >= 0)
constraints.append(lambda_beta_B >= 0)
constraints.append(theta >= 0)
constraints.append(Base + theta * M_theta - lambda_mu_A * M_mu_A - lambda_beta_B * M_beta_B + rho_sq * M_I >> 0)
objective = cp.Minimize(rho_sq)
problem = cp.Problem(objective, constraints)
problem.solve()
if retrieve == True:
return math.sqrt(problem.value), theta.value
else:
return math.sqrt(problem.value)
mu = 0.53
beta = 1.35
alpha_L = 0.05
alpha_R = 3.95
print("Begin Ternary Search")
while alpha_R - alpha_L >= 0.0001:
left = alpha_L + (alpha_R - alpha_L) / 3
right = alpha_R - (alpha_R - alpha_L) / 3
if opt_val(left, mu, beta) < opt_val(right, mu, beta):
alpha_R = right
else:
alpha_L = left
opt_alpha = (alpha_L + alpha_R) / 2
opt_rho, opt_theta = opt_val(opt_alpha, mu, beta, True)
print("Optimal alpha, theta", opt_alpha, opt_theta)
print("Optimal contraction factor", opt_rho)
print("Check with Theorem 4.1.", THM_4_1_unscaled(opt_alpha, opt_theta, mu, beta))
print("Begin Graphing")
X = np.linspace(0.25, 3.75, 50)
Y = np.array([opt_val(alpha, mu, beta) for alpha in X])
plt.plot(X, Y)
plt.show()
plt.savefig("Graph.PNG")
print("Finished!")
|
cs |
여기서 얻는 결론은 $\mu = 0.53$, $\beta = 1.35$일 때, optimal parameter는 $$\alpha_{*} = 1.5949751, \quad \theta_{*} = 1.4244099$$이고, 이때 얻어지는 optimal contraction factor는 $$\rho_{*} = 0.5010598$$이라는 것이다. 또한, 이 경우에 대한 $\rho^2_{*} (\alpha)$의 그래프를 그려서 unimodal function임을 확인할 수 있다. 그래프는 아래와 같다.
당연하지만, $x$축은 $\alpha$의 값, $y$축은 $\rho^2_{*}(\alpha)$의 값이다. 이렇게 Task 2와 논문 정리도 끝 :)
'수학 > Optimization' 카테고리의 다른 글
| Acceleration Overview (2) | 2021.03.28 |
|---|---|
| Nesterov's Estimate Sequence (0) | 2021.03.15 |
| [Computer-Assisted Proofs in Optimization] Operator Splitting Performance Estimation Problem - 2 (0) | 2021.02.23 |
| [Computer-Assisted Proofs in Optimization] Operator Splitting Performance Estimation Problem - 1 (0) | 2021.02.23 |
| [Computer-Assisted Proofs in Optimization] Performance Estimation Problem (0) | 2021.02.23 |