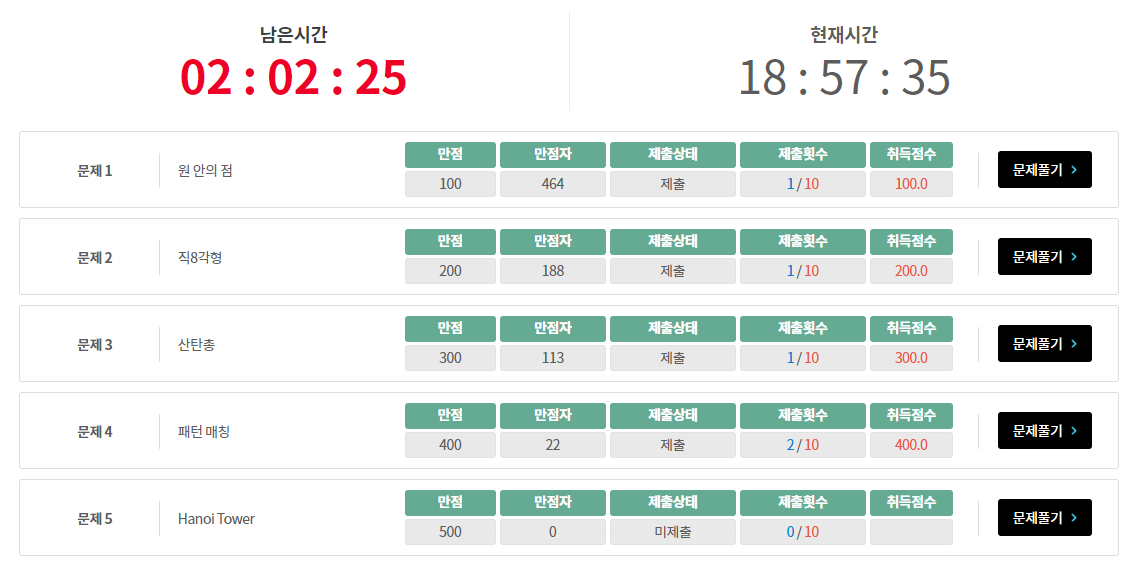
5번은 긁기는 쉬운데 만점을 받는 사람이 없길래 그냥 건드리지 않았다. 4번도 풀었고 ^__^
1번 : 원 안의 점
naive 하게 $-R \le x, y \le R$인 점을 모두 시도하면 $\mathcal{O}(R^2)$ 풀이가 나온다.
답을 $\mathcal{O}(R)$에 구하기 위해서는, $x$ 하나를 고정하고 가능한 $y$의 개수를 $\mathcal{O}(1)$에 구하면 된다.
$x^2+y^2 \le R^2-1 \iff -\sqrt{R^2-1-x^2} \le y \le \sqrt{R^2 -1-x^2}$임을 계산하면, 가능한 $y$의 개수가 $$2 \lfloor \sqrt{R^2 - 1 - x^2} \rfloor + 1$$임을 알 수 있다. 이는 sqrt 함수를 사용하거나 이분탐색을 해서 빠르게 계산할 수 있다.
점 $(x_1, y_1), \cdots (x_8, y_8)$이 있을 때, 적당한 $X, Y$를 골라서 이 점들을 $$(X, Y), (X, Y+K), (X+K, Y+2K), (X+2K, Y+2K)$$ $$(X+3K, Y+K), (X+3K, Y), (X+2K, Y-K), (X+K, Y-K)$$와 같도록 해야 한다. 각 8개의 점을 직8각형의 8개의 점에 대응시키는 방법에는 총 $8!$가지가 있다. 이러한 방법을 하나 고정시키고 생각하자.
예를 들어, $(x_1, y_1), \cdots , (x_8, y_8)$이 위 8개의 점과 순서대로 대응된다고 가정하자. 이 경우, 움직여야 하는 총 거리는 $$|x_1 - X| + |y_1 - Y| + |x_2 - X| + |y_2 - (Y+K)| + |x_3 - (X+K)| + |y_3 - (Y+2K)|$$ $$+|x_4 - (X+2K)| + |y_4 - (Y+2K)| + |x_5 - (X+3K)| + |y_5 - (Y+K)| + |x_6 - (X+3K)| + |y_6 - Y|$$ $$+|x_7 - (X+2K)| + |y_7 - (Y-K)| + |x_8 - (X+K)| + |y_8 - (Y-K)|$$가 되며, 우리의 목표는 이 식의 최솟값을 구하는 것이다.
첫 번째 관찰은 위 식에서 $X, Y$가 각각 독립적으로 나온다는 것이다. 위 식에서 $X$가 등장하는 부분만 살펴보면, $$|X-x_1| + |X-x_2| + |X - (x_3-K)| + |X - (x_4-2K)|$$ $$+ |X - (x_5-3K)| + |X - (x_6-3K)| + |X - (x_7 - 2K)| + |X - (x_8 -K)|$$ 두 번째 관찰은, $x_i$들과 $K$가 이미 알고 있는 값이므로, 이 식은 이미 알고 있는 값 $c_1, c_2, \cdots, c_8$에 대해 $$\sum_{i=1}^8 |X - c_i|$$ 형태로 쓸 수 있다는 것이다. 이 식은 $X$가 $c_i$들의 "중간"에 있을 때 최솟값을 가진다.
확인하고 싶다면, 위 식을 그래프로 그려보자. 또한, 이 때 최솟값은 $c_i$들 중 최대 4개에서 최소 4개를 뺀 값이 됨을 확인할 수 있다.
$Y$에 대한 부분도 이렇게 최솟값을 구할 수 있으며, 두 결과를 합치면 식의 최솟값을 구할 수 있다. 이를 $8!$번 반복하면 해결.
시간복잡도는 $n$이 점의 개수라고 하면, $\mathcal{O}(n! \cdot n \log n)$ 정도로 볼 수 있을 것이다.
정말 피곤한 문제였다. 진짜 부분합만 알면 풀 수 있는데, 깔끔하게 안 풀어서 그런지 계산이 너무 귀찮았다.
이제부터 모든 것을 수식으로 설명한다. 하지만 실제로 문제를 풀거나 이 풀이를 읽을 때는 그림을 그려가면서 생각하는 것이 좋을 것이다.
배열은 1-index를 사용하여, $1 \le i, j \le N$에 배열 $a$가 채워졌다고 생각하도록 하겠다.
우선, 목표로 하는 함수인 $$ \text{score}(Y, X) = \sum_{|y-Y| + |x-X| \le K-1} (K-|y-Y|-|x-X|) \cdot a[y][x]$$를 정의하면, 우리의 목표는 $\text{score}$의 최댓값을 찾는 것이다. 우선 $Y$ 또는 $X$가 $-K$ 미만이거나 $N+K$ 초과면, $\text{score}$ 함수가 $0$이 됨을 확인할 수 있다.
그러니 $-K \le X, Y \le N+K$인 경우만 계산하면 된다. 우리의 궁극적인 목표는 $\text{score}$ 함수를 이 범위 전체에 대해서 $\mathcal{O}((N+K)^2) = \mathcal{O}(N^2)$ 시간에 계산하는 것이다. 이를 위해서는 $\text{score}$ 함수가 $(Y, X)$가 한 칸 움직였을 때 어떻게 변화하는지 알아볼 필요가 있다.
이 값을 분석하는 가장 좋은 방법은 각 $(y, x)$에 대해 $a[y][x]$의 계수를 찾는 것이다. 그림을 그려 풀 때도 비슷하다.
우선 생각해보면 $|y-Y|+|x-X|$와 $|y-Y|+|x-(X-1)|$이 모두 $K$ 이하인 경우, $a[y][x]$의 계수는 $$|x-X+1| - |x-X|$$가 된다. 이 값은 $x \ge X$에서 $1$이고 $x \le X-1$에서 $-1$임을 알 수 있다.
$|y-Y|+|x-X|$나 $|y-Y|+|x-(X-1)|$ 중 하나라도 $K+1$ 이상인 경우, 둘 다 $K$ 이상이 되어 계수는 $0$이다. 즉,
$$\text{score}(Y, X) - \text{score}(Y, X-1) = \sum_{|y-Y| + |x-X| \le K-1, x \ge X} a[y][x] - \sum_{|y-Y| + |x-X+1| \le K-1, x \le X-1} a[y][x] $$가 되고, 비슷한 원리로 계산하면 $$\text{score}(Y, X) - \text{score}(Y-1, X) = \sum_{|y-Y|+|x-X| \le K-1, y \ge Y} a[y][x] - \sum_{|y-Y+1|+|x-X| \le K-1, y \le Y-1} a[y][x]$$를 얻는다. 그러니까 이제 필요한 것은 네 종류의 "삼각형 부분합"이며, 이들 역시 같은 방법으로 계산이 가능하다.
예를 들어, "1사분면에 대한 삼각형 부분합"을 $$Q1(Y, X) = \sum_{|y-Y| + |x-X| \le K-1, y \le Y, x \ge X} a[y][x]$$라 하자. 이 값을 계산하기 위하여, 다시 인접한 $Q1$ 값의 차이를 계산해보면, $$Q1(Y, X) - Q1(Y, X-1) = \sum_{|y-Y| + |x-X| \le K-1, y \le Y, x \ge X} a[y][x] - \sum_{|y-Y| + |x-X+1| \le K-1, y \le Y, x \ge X-1} a[y][x]$$인데, $a[y][x]$의 계수를 생각해보면 다음과 같은 결과를 얻을 수 있다. 그림을 그려서 생각하는 게 편하다.
부분문제 2까지는 최근 IOI 선발고사에서 나온 문제와 같고, 이 아이디어를 확장하면 문제를 해결할 수 있다.
저 동치 조건을 깔끔하게 나타낼 방법을 찾는 것이 이 문제를 해결하는 핵심이다.
결론부터 말하자면, 각 문자열의 각 문자에 대해서 "마지막으로 그 문자가 나온 위치까지의 거리"를 생각하면 동치 조건이 깔끔해진다. 예를 들어,
superguesser의 경우 순서대로 마지막으로 그 문자가 나온 위치까지 거리가 -1, -1, -1, -1, -1, -1, 5, 4, 8, 1, 3, 7가 된다.
abcdefbdaade도 역시 순서대로 마지막으로 그 문자가 나온 위치까지 거리가 -1, -1, -1, -1, -1, -1, 5, 4, 8, 1, 3, 7가 된다.
단, -1은 이전에 그 문자가 나오지 않았음을 의미한다.
또한, 이 두 문자열은 동치임을 직접 확인할 수 있으며, 일반적으로도 이렇게 두 문자열의 동치 여부를 확인할 수 있음을 증명할 수 있다.
이제 가장 "자연스러운" 접근은, 문자열을 위와 같이 숫자 형태로 전환시킨 다음, KMP를 쓰는 것이다.
이 접근은 다 좋은데, -1을 처리하는 것에 약간의 신경을 써야 한다. 예를 들어, KMP를 쓰면 기본적으로 하는 접근이 $[i-fail[i]+1, i]$가 전체 문자열의 prefix와 같다는 것이다. 여기서 다음 문자를 확인하여 이 prefix를 연장시킬 수 있는지 확인해야 한다. 만약 실제 prefix에서 $fail[i]$번째 문자에 대응되는 값이 -1이라면, 이는 이 문자가 prefix에서 지금까지 등장하지 않은 문자임을 의미한다. 이를 확인하기 위해서는 단순히 $i+1$번째 문자에 대응되는 값이 -1임을 확인하면 안되고, 그 값이 -1이거나 $fail[i]$를 초과하는지 확인해야 한다. 즉, KMP에서 지금 확인하고 있는 suffix의 범위를 넘어가는 경우를 역시 고려해주어야 한다.
I played GoogleCTF Quals as a member of Super Guesser. We reached 9th place, which is good enough for a place in the Finals!
I solved all five cryptography problems, one (pythia) with barkingdog. While this was good work, I'm still sad that I couldn't solve the misc "cryptography" problem due to lack of time and creativity (and probably work ethic as well). Here's how we solved the cryptos.
Now we see the vulnerability! The server checks our point lies on our curve, but then takes the coordinates modulo $P$, which is the modulo from the server's curve. Since there are no restrictions on the coordinate size, by Chinese Remainder Theorem, we have a complete control over the final coordinates taken modulo $P$. The server takes this faulty point and multiply it by $D$, the ECDSA secret key.
Step 3 : The Invalid Curve Attack
Turns out that the problem now reduces to a known attack called the invalid curve attack.
Basically, when we work on the Weierstrass curve $y^2 = x^3 + ax + b$, the standard implementations for adding and doubling points never uses the value of $b$. It only uses the value of $a$ and the one or two points of the input.
Therefore, if the server considers a point $(X, Y)$ and considers it as a point on $y^2 = x^3 + ax + b$ while multiplying a scalar to it, it actually performs valid scalar multiplication, although the computation is on the point $y^2 = x^3 + ax + b'$, where $$b' \equiv Y^2 - X^3 - aX \pmod{p}$$
Since we have full control on $(X, Y)$, the result after the coordinates are taken modulo $P$, we can actually select any curves of the form $y^2 = x^3 - 3x + b$. To exploit this even further, we can use the small subgroup attack. Consider we take find a curve $y^2 = x^3 - 3x + b$ which has an order which is a multiple of a small prime $m$. We can then take a point $(X, Y)$ on this curve with order $m$. If we send this point, the shared secret will be the first coordinate of a scalar multiple of $(X, Y)$, which there are only at most $m$ candidates.
Since we can easily determine if our guess for a shared secret is valid by checking whether we receive a reply or not, we can test all $m$ candidates. However, the shared secret is just the first coordinate of the elliptic curve point. This means we will actually get two possible candidates for $D \pmod{m}$, so something like $D \equiv \pm l \pmod{m}$, since the additive inverse of a point has the same first coordinate.
If we gather a lot of such information, we will be able to find a sufficiently small candidates for $D$ by Chinese Remainder Theorem.
To do so, we choose the "signs" in each modulo relation, compute $D$ by Chinese Remainder Theorem, and repeat.
Step 4. Implementation and Finish
Choosing the Modulo $m$ - Prime : I chose the modulo $m$ to be prime, since they give a lot of information in a sense that $m$ will have GCD 1 with all the previous modulos I used. If you get $\pmod{m_1}$ and $\pmod{m_2}$ information, then you will get $\pmod{\text{lcm}(m_1, m_2)}$ information in total by Chinese Remainder Theorem. Therefore, having $\gcd(m_1, m_2) = 1$ usually helps.
Choosing the Modulo $m$ - Size : This is quite important. If we take larger $m$, the number of modulo relations we need to take becomes smaller. This implies that we have an easier offline bruteforce of choosing signs, computing Chinese Remainder parts, and either ECDSA public key verification or AES decryption. However, choosing larger $m$ also implies that we have to search more elliptic curves to find a appropriate one, and we also need to interact with the server more to decide what $D \pmod{m}$ can be. If we take small $m$, everything becomes the opposite. I chose $m$ to be a prime between $300$ and $1000$. In my case, 25 relations were sufficient to find $2^{25}$ candidates for $D$, which is definitely a feasible number of candidates for final offline bruteforce.
Multiprocessing : I used it to speedup both the server computation and the offline bruteforce.
Trick from rbtree : Instead of bruteforcing the signs, one can just solve for $D^2$ by CRT and take sqrt. In this case, you would need twice more information on $D \pmod{m}$, but you don't need the extra bruteforce. Great idea from rbtree, shared after contest!
pythia (65 solves)
This was a tricky problem for me, as I found the solution nearly immediately but struggled to write the exploit.
Step 1 : Basic Analysis
There are a total of $26^3$ possible passwords, each corresponding to a 16 bytes AES-GCM key.
There is a password (key) we have to find. We must do it using around 48 queries of the following type.
We can send some nonce/ciphertext/tag to be AES-GCM decrypted with the key without any associated data.
The only response we get from the queries are whether or not the decryption process was successful.
Note that there are actually 150 queries and 3 passwords, but since each three problems are independent, we can just focus on one.
Step 2 : Reducing the Problem and Finding Attack Vector
In these types of problems, it's best to halve the number of candidates by each query.
To do so, we have to figure out how to build some nonce/ciphertext/tag that accepts all of the keys from a given set.
If we can do this, we can simply perform a "binary search" to get each password. This is a good time to look at how AES-GCM works.
Step 3 : AES-GCM and Polynomial Fun
Here, we only consider the case where there are no associated data and we have 12 byte nonce. Everything is in $GF(2^{128})$.
Let $K$ be the key, $C = C_0 || C_1 || \cdots || C_{n-1}$ the ciphertext, and $IV$ the nonce. We now calculate $$H = AES_K(0^{128}), \quad J_0 = IV || 0^{31} || 1, \quad L = 0^{64} || len(C)$$
The tag $T$ is now calculated as $T = C_0 H^{n+1} + C_1 H^n + \cdots + L \cdot H + AES_K(J_0)$.
Let's fix $IV= 0^{96}$. If we know $K$ and $n$, then we can calculate $H, J_0, L, AES_K(J_0)$.
Now we want the polynomial coefficients $C_0, C_1, \cdots, C_{n-1}, T$ such that $$C_0 H^{n+1} + C_1 H^n + \cdots + L \cdot H + T = AES_K(J_0)$$ for a given set of $K$. To be exact, if we have $K_1, K_2, \cdots , K_m$ as a target set of keys, we compute the corresponding $H_1, H_2, \cdots , H_m$.
Then, we will try to find $n, C_0, C_1, \cdots , C_{n-1}, T$ such that $$C_0 H_t^{n+1} + C_1 H_t^n + \cdots + C_{n-1} H_t^2 + L H_t + T = AES_{K_t}(J_0)$$ for each $1 \le t \le m$. This is starting to look like Lagrange interpolation, with the caveat that $L$ is determined by $n$.
Take $n=m$. Let $f(x) = C_0 x^{m+1} + \cdots + C_{m-1} x^2 + L x + T$, which is a polynomial we want to find.
Our desired $f$ must satisfy $f(H_t) = AES_{K_t}(J_0)$ for each $1 \le t \le m$.
This $f$ can be found directly with Lagrange interpolation, and $f$ will have degree at most $m-1$. However, we have to set $f$'s coefficient of $x$ to be equal to $L$. This can be done by adding some scalar multiple of $g = (x-H_1)(x-H_2) \cdots (x-H_m)$.
However, if this $g$ has the coefficient of $x$ equal to $0$, we cannot control this coefficient by adding $g$.
In this case, we have to control it by multiplying some random degree 1 polynomial.
Finally, note that we can put any number of zero blocks at the front of the ciphertext to meet the length requirement if $\deg f < m+1$.
There are a lot of methods to handle these sepcial cases, (i.e. $g$ can't control the coefficient) and the solution writeen by barkingdog is a bit different from what I wrote as well. He handled these cases by simply adding a few random points for the interpolation part of $f$.
This makes $g$ and it's coefficients much more random, making it unlikely for the coefficient to be zero.
I would like to note that is error is a very unlikely case, so not error-handling these special cases won't hurt.
Step 4 : Implementation Details
FastInterpolation : If we try to find $C_i, T$ with a system of linear equations, the algorithm will take $\mathcal{O}(n^3)$ time which is quite slow. A relatively naive lagrange interpolation takes $\mathcal{O}(n^2)$ time. I suggest just using SageMath's lagrange polynomial function.
Binary Search: If we just use standard binary search, we would have to compute $f$ for a set of $26^3/2$ keys. This is quite large for us to handle, and it may not even fit the payload size. Since we have much more than $\log(26^3) < 15$ queries per password, we can try to make our interpolation computation easier at the cost of using more queries. Here is one way to do so - we divide the set of $26^3$ keys into $40$ batches of size around $440$. We find which batch the key is in, and then use standard binary search. This fits in the query limit quite tightly. Note that if we found the batch that has the key, we do not need to check the other batches.
Cache : Note that the payload to test whether the key is in a certain set can be precomputed beforehand. Therefore, by using a cache or hashmap or whatever, we can save ourselves from repeating the same computation over and over again. This is especially useful when we are testing the $40$ batches - we will test the same batches for all three passwords, and computing the payload for all of them takes quite a while. By saving these payloads, we can save quite a lot of time on the exploit.
AES-GCM : endian stuff are very confusing to figure out, so you have to really concentrate
h1 (23 solves)
Step 1 : Basic Analysis
We have some ECDSA looking stuff (it's actually just elliptic curve operations with Jacobians)
We have some signatures, but we do not know any public key.
Alice has sent two messages and signatures, but one of the messages contain the unknown flag.
Bob has sent two messages and signatures, and we know both messages and their hashes.
We also know the AES encrypted messages (one contains flag) with the shared secret as the key.
The ECDSA nonce is yelling loudly at us to attack it which we obviously have to do.
Step 2 : Reducing the Problem and Finding Attack Vector
Obviously there is something going on with the custom RNG, and it becomes apparent if we read the code.
1
2
3
4
5
6
7
8
9
10
11
12
13
def RNG(nbits, a, b):
nbytes = nbits //8
B = os.urandom(nbytes)
return a * sum([B[i] * b ** i for i inrange(len(B))]) % 2**nbits
def Sign(msg, d):
h = hashlib.sha512(msg)
z = Transform(int.from_bytes(h.digest(), 'big'), h.digest_size*8)
We see that $n$ is $512$ bits, and our RNG call uses $b = 2^{32}$. Therefore, in the RNG call, the nonce can be written as $$ \sum_{i=0}^{15} a \cdot byte_i \cdot 2^{32i}$$ since all values from $i \ge 16$ becomes $0$ modulo $2^{512}$. Note that $255a < 2^{32}$, so no modulo operations are needed.
Since each $byte_i$ has 8 bit of "entropy", in total the RNG has only 128 bits of "entropy", which is horrible.
This also means that each complete message/signature pair gives us around 384 bits of information on the secret key.
Since we have two such pairs for Bob's secret key $db$, we should be able to extract this value.
Clearly, computing the shared secret solves the problem, so we just need the public key of Alice.
This is not hard, as given one complete message/signature you can recover the public key. This is even in wikipedia.
NOTE : There may be more than one public key possible, so try all of them to find the flag.
Therefore, clearly getting the secret key $db$ is the hardest part of the challenge, unless you are rkm0959 who doesn't know fundamentals.
rkm0959 wonders how to get da (private) while he only needs Qa (public)
Step 3 : Yet Another Inequality Solving with CVP!
Consider the message, signature pair $(r_1, s_1, z_1)$ and $(r_2, s_2, z_2)$, where $z$'s are the hashes. We know $$ \left( \sum_{i=0}^{15} a \cdot byte_{1, i} \cdot 2^{32i} \right) \cdot s_1 \equiv z_1 + r_1 d \pmod{n}$$ $$ \left( \sum_{i=0}^{15} a \cdot byte_{2, i} \cdot 2^{32i} \right) \cdot s_2 \equiv z_2 + r_2 d \pmod{n}$$ Since we can, we will remove $d$ from this system by writing $$ \left( \sum_{i=0}^{15} a \cdot r_2 \cdot byte_{1, i} \cdot 2^{32i} \right) \cdot s_1 - \left( \sum_{i=0}^{15} a \cdot r_1 \cdot byte_{2, i} \cdot 2^{32i} \right) \cdot s_2 \equiv z_1r_2 - z_2r_1 \pmod{n}$$ Now we can consider $33$ variables $byte_{1, i}, byte_{2, i}, t$ for $0 \le i \le 15$, and use the $33$ inequalities $$\left( \sum_{i=0}^{15} a \cdot r_2 \cdot byte_{1, i} \cdot 2^{32i} \right) \cdot s_1 - \left( \sum_{i=0}^{15} a \cdot r_1 \cdot byte_{2, i} \cdot 2^{32i} \right) \cdot s_2 + tn = z_1r_2 - z_2r_1 $$ $$ 0 \le byte_{1, i}, byte_{2, i} \le 255$$ and plug this into Inequality Solving with CVP repository. This gives us $db$ and it solves the problem.
tonality (30 solves)
Step 1 : Basic Analysis
We get the ECDSA public key $P = dG$ and two messages.
We can send a integer $t$, and we get the signature of first message signed with private key $td$.
We now have to forge any signature of the second message with private key $d$.
There's nothing really going on in this problem, so we just need to use the first query very well.
Denote the two messages $m_0, m_1$ and their hashes $z_0, z_1$. Denote the integer we will send as $t$.
We will receive the signature $r_0, s_0$ such that the point $$ (z_0 / s_0) G + (r_0 / s_0) tP $$ has the first coordinate equal to $r_0$. Here, the integer division is done modulo $n$, the order of elliptic curve.
We now have to forge a signature $r_1, s_1$ such that the point $$ (z_1 / s_1) G + (r_1 / s_1)P$$ has the first coordinate equal to $r_1$. Here, the integer division is done modulo $n$, the order of elliptic curve.
We wish to solve this in the easiest way possible - and this will happen when $$ z_0/s_0 = z_1/s_1 , \quad (r_0 / s_0)t = (r_1/s_1), \quad r_0 = r_1$$ which can be rearranged as $$t = z_0 / z_1, \quad r_1 = r_0, \quad s_1 = z_1s_0/z_0$$ and submitting this to the server solves the problem.
story (32 solves)
Step 1 : Basic Analysis
We have to send a sufficiently large UTF-8 string to the server.
We receive the CRC16, CRC32, CRC64 values of the sent string back.
We also receive the desired CRC16, CRC32, CRC64 values from the server.
We have to make a string with the desired CRC values, with the same lowercase text as the original string.
Step 2 : Finding Attack Vector
The obvious problem is that CRCs are not meant to be an encryption of some sort. They satisfy the powerful relation $$crc(x) \oplus crc(y) \oplus crc(z) = crc(x \oplus y \oplus z)$$ which can be used to solve this problem relatively easily.
There are several ways to solve this problem, maybe even using finite field representation of CRC. However, I still think the method in Step 3 is much easier to deal with than dealing endian issues and figuring out which polynomial is actually used to compute CRC.
Step 3 : Exploiting with Linearity
Denote $x_{16}, x_{32}, x_{64}$ be the CRC values of "a" * 256.
Also, for each $0 \le i \le 255$, we denote $x'_{i, 16}, x'_{i, 32}, x'_{i, 64}$ as the CRC values of "a" * 256 but the $i$th 'a' is changed to 'A'.
These values can be computed by 257 server interactions, and the CRC computation is of course deterministic.
Now we can build the CRC values of any length 256 string with 'a' and 'A' only. We start with $x_{16}, x_{32}, x_{64}$, and if the $i$th character is 'A' instead of 'a', we XOR the values $x'_{i, 16} \oplus x_{16}, x'_{i, 32} \oplus x_{32}, x'_{i, 64} \oplus x_{64}$ to our CRC result.
Now changing 'a' to 'A' appropriately for the result CRC to match the target is something like a subset sum problem with bitstring XOR.
Of course, looking at each bit separately, this is nothing more than a system of linear equations over $\mathbb{F}_2$.
We solve this, find the locations where we have to change the lowercase/uppercase, and get the flag.
$b_i = a_{i-t} | a_{i+t}$로 정의된 bit string $b$가 주어졌을 때, 사전순으로 가장 앞선 $a$를 구하는 문제다.
단, index가 가능한 범위 밖인 경우 값은 $0$이라고 생각하도록 한다. 또한, 조건을 만족하는 $a$가 존재함은 보장된다.
먼저 $b_i = 0$이면 $a_{i-t} = a_{i+t} = 0$임이 강제되며, 이렇게 둘 경우 $b_i = 0$ 역시 만족함을 알 수 있다.
이에 해당되는 $a$의 bit에 0을 넣는 것을 확정하고 나면, 이제 $b_i = 1$ 형태의 조건들만 남았다.
이들은 결국 $a$의 두 bit 중 적어도 하나가 1이라는 의미고, 이는 직관적으로 봤을 때 1을 더 넣으면 넣을수록 만족하기 쉬운 조건이다.
그러니, 앞서 0으로 확정된 bit가 아닌 임의의 bit에 대해서는 그냥 1로 두면 조건을 만족하는 $a$가 될 것이다.
이제 문제는 사전순으로 가장 앞선 $a$를 구하는 건데, 이런 문제가 그렇듯 앞부터 보면서 0을 넣을 수 있는지 판별하면 된다.
$a_i = 0$이 가능한지 고려해보자. 먼저 $a_i = 0$이 앞서 확정되었다면 굳이 고려를 할 필요도 없다.
만약 $i-t$가 범위에 있고 $b_{i-t} = 1$이라면, $a_{i-2t}$ 또는 $a_i$가 $1$이 되어야 한다. $a_{i-2t}=0$이라면, 여기서 $a_i = 1$이 강제된다.
만약 $i+t$가 범위에 있고 $b_{i+t}=1$이라면, $a_i$ 또는 $a_{i+2t}$가 $1$이 되어야 한다. $a_{i+2t}$가 이미 $0$으로 확정되었다면, 여기서 $a_i = 1$이 강제된다.
이를 제외한 경우에서는, $a_i = 0$을 해도 문제가 되지 않는다. $a_i$가 영향을 주는 $b$의 값은 $b_{i-t}$, $b_{i+t}$이며, 이들의 값을 $a_i = 0$으로 두면서도 정확하게 맞춰줄 수 있기 때문이다. 특히, 마음에 걸릴 수 있는 유일한 부분이 $a_i = 0$으로 두면서 후에 $a_{i+2t}$를 $1$로 둔 것인데, 애초에
$a_i = 1$로 두면 무조건 $a_i = 0$으로 두는 것보다 사전순으로 뒤고, 그러니 $a_i = 0$인게 이득이고
$a_{i+2t}$는 확정되지 않은 bit이므로 $a_{i+2t} = 1$으로 두었다고 해서 조건을 만족하는 게 "어려워지지 않는다"
애초에 이 경우에는 $a_i = 0$으로 두고 확정된 bit를 제외한 뒤의 모든 bit를 1로 두면 조건을 만족하게 되어있다.
어쨌든 이런 식으로 bit를 계산하면 $\mathcal{O}(n)$에 모든 계산을 할 수 있다. 2번 문제인 것 치고는 약간 까다로웠다.
$2 \times m$ 직사각형에 사람들을 배치한다. 사람들은 총 $n$개의 그룹으로 나뉘어 있으며, 각 그룹에는 5명 이상이 있다.
각 사람들은 스트레스 지수 $w$를 갖는데, 자신의 이웃에 자신과 다른 그룹에 속하는 사람이 있다면 그런 사람의 수와 $w$의 곱만큼 스트레스가 오른다.
우리의 목표는 스트레스 지수의 총합을 최소화하는 것이다. 제한은 전체적으로 큰 편이다.
동적계획법을 쓰기 어렵게 생긴 제한인만큼, 한방에 문제를 푸는 방법이 필요해보인다.
그룹 $S$ 하나를 고정해보자. $S$의 사람들이 스트레스를 느낄 때는, $S$와 $S^C$가 한 변을 공유할 때다.
그러니까 $S$의 둘레의 (단, 직사각형의 둘레는 제외한다) 길이가 길면 길수록 $S$ 전체의 스트레스가 커진다.
이는 $S$의 사람들이 뭉쳐있어야 스트레스가 적을 것 같다는 직관과도 거의 같은 결과다.
"$S$의 둘레"를 생각해보면, 전체 직사각형의 길이 2의 세로변을 잠깐 무시하고 생각해보면
$S$의 크기가 짝수인 경우, 직사각형 형태를 이루도록 하면 둘레가 4가 된다.
특히, 이 경우 $S$에서 서로 다른 4명의 사람들이 정확히 $S^C$의 한 사람과 만나게 된다. 이 사람들은 스트레스 지수가 작을수록 좋다.
$S$의 크기가 홀수인 경우, 직사각형에 하나 튀어나온 형태를 만들면 둘레가 5가 된다.
특히, 이 경우 $S$에서 서로 다른 4명의 사람들이 $S^C$의 사람과 만나게 된다. 4명 중 정확히 한 명은 $S^C$를 두 명 만나고, 나머지는 한 명 만난다.
물론, 두 명 만나는 사람의 스트레스 지수가 가장 작아야하며, 나머지의 스트레스 지수 역시 작을수록 좋다.
그리고 조금 열심히 생각해보면 이게 진짜 최적임을 납득할 수 있다. 또한, 홀수 크기의 그룹이 짝수개 존재하므로, 홀수 크기의 그룹끼리 서로 맞닿아 직사각형을 이루도록 하면 배치 역시 어렵지 않다. 이제 문제는 길이 2의 세로변을 처리하는 것이다. 길이 2의 세로변에 걸쳐서 $S$를 배치한다면, $S$에서 스트레스를 받는 4명 중 2명은 (이들은 4명 중에서 스트레스가 많은 두 명일 것이다) 전체 직사각형의 세로변의 도움을 받아 스트레스를 받지 않아도 된다.
단순하게 생각하면, 여기서도 "가장 이득을 보는 그룹"을 양쪽 끝에 배치하여 세로변의 도움을 받을 수 있도록 하면 된다.
그런데 이게 이렇게 단순하지는 않은 게, 배치를 양쪽 끝에 하면 앞서 언급한 최적의 배치를 만드는 것이 어려울 수 있기 때문이다.
홀수 크기의 그룹이 정확히 2개 있고, 짝수 크기의 그룹이 여러 개 있다고 하자. 만약 홀수 크기의 그룹 2개가 양쪽 끝에 놓인다면, 짝수 크기 그룹을 직사각형 형태로 사용할 수 없고, 직사각형에서 양쪽에 한 개씩 튀어나온 형태로 사용해야 한다. 이때 짝수 크기 그룹에서 희생을 더 해야한다. 나머지 경우에서는 어떤 크기의 그룹을 양쪽에 배치해도, 우리가 생각하는 "최적의 배치"가 (직사각형 최대한 사용, 홀수 크기 2개 직사각형으로 만들기) 가능하다. 이제 열심히 케이스 분류.
주어진 조건을 두 변수 사이의 간선이라고 보면, 연결 컴포넌트에 안에서는 모든 차이 계산이 가능하다.
문제가 되는 것은 사이클, 특히 한바퀴 돌았는데 합이 0이 되지 않는 사이클이다. 이 경우, 사이클에 도달할 수 있는 모든 정점들은 모순된 상태가 된다.
그러니, disjoint set 자료구조를 가져왔을 때 대강
두 정점이 같은 disjoint set에 속하지 않으면 Not Connected
두 정점이 같은 disjoint set에 속하는데 여기에 모순된 cycle이 있으면 Conflict
두 정점이 같은 disjoint set에 속하고 모순도 없으면 계산이 가능
함을 알 수 있다. 연결관계 자체만 봤을 때 disjoint set은 자명하고, 모순을 찾거나 계산을 하는 것이 문제다.
계산을 하기 위해서, 각 disjoint set의 대표 노드를 하나 두고 각 원소가 그 대표 노드의 값보다 얼마나 큰지 저장한다.
원소들 사이의 차이는 알지만 원소 자체의 값은 모르니, 대표 노드의 값을 하나의 변수로 보고 차이만 저장하자는 의미다.
이제 간선, 즉 하나의 등식이 추가되었다고 가정하자.
만약 두 정점이 같은 disjoint set에 있다면, 모순이 있는지 바로 확인할 수 있다. 저장된 값의 차이가 입력된 값과 다르면 모순이다.
두 정점이 다른 disjoint set에 있다면, 이번에 추가된 등식은 두 disjoint set의 대표 노드 값 사이의 차이를 제공하는 정보가 된다. 이 경우, 두 disjoint set 중 하나의 대표를 전체의 새로운 대표로 정한다. 그 후, 흡수되는 집합의 각 원소들에 대해서 새로운 대표의 값과의 차이를 계산해야 한다. 이는 새로 얻어진 등식을 활용하여 할 수 있을 것이다. 물론, 두 disjoint set 중 이미 모순된 집합이 있다면 새로운 집합 역시 모순이 있다.
두 disjoint set을 합치는 과정에서 걸리는 시간이 흡수되는 집합의 크기에 비례함을 알 수 있다. 그러므로, 작은 집합을 큰 집합에 흡수시키는 small-to-large 알고리즘을 사용하면 빠른 시간에 문제를 해결할 수 있다. 또한, 각 집합을 std::set 자료구조로 저장해야 집합의 순회가 쉽다.
학교 : 1학기를 4.25/4.3으로 마무리했다. 전기전자회로에서 실수를 해서 A0가 떴고, 나머지는 A+.
돌아보면 그래도 실해석학과 복소1이 가장 재밌었다. 딥러닝은 아직도 잘 모르겠다... 시험은 그냥 수학이었고...
군대/회사 : 회사에 들어왔다. 자세한 사항은 아마 병특 확정이 되면 여기에도 쓸 수 있을 것 같다.
회사에 들어왔으니, 여기서 다양한 일을 하면서 많이 공부를 하고 싶다. 돈도 돈이지만 경험도 중요하니까..
정보처리산업기사 실기를 봤다. 이거 준비한다고 시간을 또 은근 썼는데, 지금 보면 아깝기도 하고 ㅋㅋㅋ
연구 : 공부는 계속 재밌고, 연구 주제는 계속 바뀌고 있는데 곧 "진짜" 확정이 될 것 같다..
연구 주제 외의 최적화 분야 공부는 소멤 글로 정기적으로 올라갈 것 같다. 재밌는 내용이 많다 확실히...
CTF : 당장 이번 주말이 구글 CTF고, 상당히 이를 악물고 참가할 계획이다. 팀 모두가 열심히 하면 좋겠다.
그거랑 별개로 최근에 0CTF에서 zer0lfsr+를 해결한 건 오래 기억에 남을 것 같다. 오래 고민해서 문제 푼 거 되게 오랜만임.
회사를 다니기 시작하면서 정말 시간을 아껴 사용해야 함을 느낀다.
또 더욱 많은 사람을 만나기 시작하면서 세상에는 대단한 사람이 많음을 느낀다.
열심히 해야지,, 그렇다고 노는 걸 아예 포기하기는 그렇고, "출퇴근 시간에서 모든 여가활동을 할 수 있게" 컨텐츠를 바꿀 생각.
이건 아마 한동안 오락실을 (츄니즘) 가지 못할 것 같다는 의미기도 하다. 사실 최근에 코로나가 하도 빡세진 것도 있고, 오락실을 가도 별로 성과가 나오는 것도 아니어서 오히려 잘 됐다. 어쨌든 시간을 잘 쓰는 것을 연습해야겠다... 은근 버리고 있는 시간이 많은 것 같다. 잠도 조금 줄이고,,